Difference Between Process And Thread in Linux

We always hear people using two terms very often. One is “Process” and the other is “thread”. Which one is process and which one is thread, and what differentiates the two is often confusing to many folks.
In this article, we will try to uncover each of these in the context of Linux operating system, and understand their primary differences.
Let us first start with processes, and then move to threads. The most common definition you can find about process is “It is an instance of a program, that is under execution”. What does that even mean?
In someway, you can actually compare process to objects in OOP(ie: object oriented programming). In object oriented programming, an object is also defined as an instance of a class. Each object gets its own values and characteristics, but the object gets created by looking at the class as a blueprint. You can create numerous objects from the same class.
Related: Basics of Object Oriented Programming
Similarly, if you have a text editor program in Linux, like “vi”, userA can open a text editor(one instance of the “vi” program), userB can also open the same text editor(another instance of the “vi” program). Let us try doing that in Linux.
The below commands are fired on two separate terminals. This will open the vi text editor, and will let you create a new text file.
user1@localhost:~$ vi testfile1
user2@localhost:~$ vi testfile2
Now let us use another terminal to find out how many vi processes are running on the system.
root@localhost:~# ps aux|grep vi user2 6167 0.0 0.8 52616 8464 pts/1 S+ 11:55 0:00 vi testfile2 user1 6168 0.0 0.8 52616 8448 pts/0 S+ 11:55 0:00 vi testfile1
We can clearly see from above output that each instance of our "vi" program, has created a process of its own. This is the reason for the popular definition "Process is an instance of a program, that is under execution". If you compare this with OOP as mentioned earlier, program is similar to class, and process is similar to objects(well in someways..Not 100 percent).
Processes are completely dynamic in nature. It is continuously changing as the CPU executes instructions. Linux kernel is designed in such a way that each process has its own rights and permissions. An issue in one process cannot impact the other processes running in the system. This is because each process has its segregated address space.
Each process in the system is identified by a number called PID(the number mentioned in the second column of the previously shown output of our "vi" process is PID number. If you notice, both the processes have their own PID numbers). This number is allocated by the kernel and released for reuse when the process exits. Even if you run a command that completes within a second, it will still create a process with a PID number. If you are interested in some more administration details about processes in Linux, I would recommend reading the below article.
Read: Administering Linux Processes
If you are to do something worthwhile with Linux, you need something called as System Calls. Without system calls you cannot do most of your work (read a file, write a file,open a port).
System calls is nothing but a way for interacting with the operating system, so that operating system can do things that you do not have direct permission to. Even to create a process, you need to request the operating system to do it for you (when i say operating system, i am referring to kernel here). Remember we mentioned that each and every process (ie: an instance of a program :), now you know the definition) has a unique number associated with it called PID?. That number is also allocated by the kernel. So even that is a system call. Many programs will read and write to different files, all of which are achieved by system calls.
If you are interested in knowing a bit more about system calls, then i would recommend reading the below.
Read: Understanding System Calls in Linux
To make programmers life easier, there are C library functions for almost everything (provided by GNU C library). As I mentioned earlier, you need to use system calls for almost every operation that you do on the system(read,write,create process etc). As a programmer, you do not need to worry much about which system call to use for which operation, and how to trigger a particular system call etc. You can use C library functions, with appropriate function parameters, which will intern trigger a system call for you. For example, I do not need to know the system call to write something to a file (I will use the library function named "write" - Yes in most cases the name of the system call and library functions look similar).
Every process in Linux is created by a parent process using a library function/routine called fork(there is a system call with the same name as the function "fork"). I must actually say everything else other than INIT/systemd (the very first process with PID 1 in Linux) is created using the fork method.
There is a system call with the name fork(). The corresponding library function available is also called fork. Traditionally, fork() is the system call that creates new processes. But these days fork() system call is actually replaced by something else (although the system call itself is present, but is seldom used. It is still available for backward compatibility.)
Instead of fork(), the system call used in all recent systems for creating processes is called clone(). clone() is very similar to fork(), but has more capabilities and is versatile in nature. As clone() can do things that fork() did, along with some additional stuff, even the standard c library function named fork(), calls clone().
The bottom line is this...clone() replaces fork() in all modern systems. Even if you use fork function provided by c library, the function will intern use clone().
Before we proceed further, the main important thing to understand is that we need a structure for processes. Let us imagine that we need to store details about employees in a company. The easiest method is to create variables and assign values to them. For example, we can have variables like empname1 = "sam", empage1 = 30, emplocation1 = "california" etc. This will get messier as we grow bigger and bigger. Imagine 100 employees(how many variables we will need, and all of them with an attached numbers. That will be funny).
A better approach would be to create a structure called employee with several characteristics like name, age, location etc. When we need to add an employee, we just use the structure employee
Now you know that there should be some structure for processes as well (because there will hundreds of processes running in the system). Each and every process in Linux is created using a data structure in C called task_struct.
Do not get confused by the term "task" here. From a kernel's perspective, a task is nothing but a process. The terms "task" and "process" are one and the same.
The kernel (operating system) has the entire details of processes currently running on the system in the form of a list (called task list..it is actually a circular linked list). You can now guess the elements/items of this list. The items are task_struct structures that describes each process.
So what details does task_struct hold in terms of a process? It holds a lot of information about a process. Some of them are below. Btw, now that we know there is something called task_struct for each process, we can define a process as below.
A process is nothing but an instance of task_struct data structure, that describes the process and all its details.
| FIELD IN TASK_STRUCT DATA STRUCTURE | DESCRIPTION |
| state | You can easily guess this one when we talk about processes. Process can be in different states. Namely interruptible, uninterruptible, zombie, stopped etc. |
| ptrace | this is related to debugging a process. To trace system calls carried out by a process. |
| static_prio | Nice value for specifying process priority |
| cpus_allowed | The programmer can specify the cpu core where he wants the process to run - or allowed to run - this is where cpu affinity is set |
| ptrace_children | Child process beneath that is being traced (actually this is yet again pointing to another struct - another structure) |
| ptrace_list | Other parent processes that is tracing this process (another structure) |
| mm | As we know that task_struct fields can point to other structures (ie: similar to task_struct), this mm field points to another structure called mm_struct. This is the memory description for a particular process. Basically the physical memory pages and memory address space allocated to the process |
| exit_code, exit_signal | These fields are used to hold signals and exit codes when the process exits. This will let the parent process know how the child died |
| pdeath_signal | The signal that is sent when the parent dies |
| pid | process identifier |
| parent, children | This is again another structure pointing to parent process, and any children this process has |
| utime,stime,cutime,cstime | user time, system time, collective user time spent by process and its children, total system time spent by process and children |
| gid,uid,environment | group id, user id and environment variables available to the process |
| files | open file information - again another structure |
| signals | handlers related to certain signals, signals that are pending etc. |
| tgid | Thread group identifier (I will explain towards the end of the article) |

How does a Process gets Created?
Process creation in Linux involves two system calls. The first one creates a clone of the calling process. Let us imagine that you are going to execute the command "date" in Linux. The calling process is of course the bash shell. The first system call that creates the process as a clone of the shell process is called clone(). Irrespective of which library function is invoked, clone () will be called to create a child process. Once the child process is created, then we need to replace the executable in that process, with date command binary. This is achieved using execve() system call.
You can practically see this happening by executing the below command.
ubuntu@localhost:~$ strace -f -etrace=execve,clone bash -c '{ date; }'
execve("/bin/bash", ["bash", "-c", "{ date; }"], [/* 21 vars */]) = 0
clone(child_stack=0, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, child_tidptr=0x7f531bc639d0) = 19163
strace: Process 19163 attached
[pid 19163] execve("/bin/date", ["date"], [/* 21 vars */]) = 0
Wed Apr 25 08:25:49 UTC 2018
[pid 19163] +++ exited with 0 +++
--- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=19163, si_uid=1000, si_status=0, si_utime=0, si_stime=0} ---
+++ exited with 0 +++
The child process is usually a copy of the parent. Being said that, the things that will differ is the PID number, PPID (parent process id) which will be set to the caller pid (bash process id in our case). The child will also have a new pending signals (it does not inherit pending signals from parent. Just imagine, if there was already several signals to parent process id, that was yet to execute, the child should not get those when clone happens).
The execve() system call replaces the child process with an executable program (in our example, date command with absolute path..See the strace output above). This will replace the address space with new one for date command. The copied address space for our new process gets thrown away as soon as execve happens.
Remember the fact that every process in Linux comes under something called as a tree. People call this tree as process tree. You can see it by executing pstree command in Linux. Every process will have a parent and 0 or more children (and it all starts from the bigdaddy INIT with pid 1).
We understand from the above shown strace command output that each child is born by cloning the parent, and then replacing the binary to execute using execve() call (which will throw away the copied address space ).
Let us imagine a situation where we do not need execve(). We just need fork() call which uses clone() internally to create a new child process, that is exactly the copy of the parent process.
There are cases where you do not need execve(). For example, let us imgine you need a lot of worker process to do something parallely. May be for accepting incoming tcp connections to your application ?.
In those cases, you really do not need execve(). Because you are not going to replace the executable binary. You just need one more process to do stuff in parallel. Although we say the child process is a copy of the parent with same address space, it actually does not copy the address space. It only copies if the child is going to do some write operation (otherwise why do we even need a copy if there is no modification being done on the copy)
It is only copied when the child attempts to change something. This way the time and resources taken to copy the address space is saved. This is called Copy on Write Method. This is generally refferred to as COW.
Now you know why Linux implemented creation of processes using combination of two calls (clone and execv).
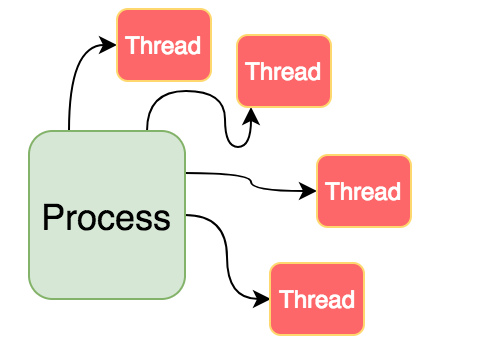
If we have an application that can only do one thing at a time, it is really bad. Don’t you think so ?. For example, imagine a web browser that will only let you browse one single page at a time, or an app that can only read inputs from keyboard at a time, and nothing else. That is unimaginable in today’s world. This is where thread steps in.
A process can have multiple threads. Meaning threads will be part of a process (all threads of the same process will share same PID).
Well if you want multiple things to happen at the same time, it can be achieved using multiple processes. Why threads?. This is because communication between processes is not that simpler when we think from an application standpoint. Sharing data between processes (in Linux you have Pipes, or sockets etc to share things between processes) has some overhead involved - and is comparatively slow. Context switching between threads are faster compared to switching between processes.
The kernel keeps on switching between tasks in a timely manner. This is to fairly share CPU among all tasks (processes) on the system. Switching a process, involves a bit more overhead compared to threads. This is because threads are always on a shared address space, so less things to replace when processor changes the context of execution from one thread to another.
How are threads created in Linux?
Remember we learned that fork() system call is seldom used these days, instead clone() is used for creating processes?. The same clone() is used for creating threads in Linux. Yes. What matters is the parameters passed to the clone() system call.
If the clone system call has below parameters, then it will create something similar to thread, instead of a child process.
clone(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND, 0);
The things that you see as parameters to the clone function above specifies what needs to be shared while creating the new process/thread.
Actually the above clone() system call will create a child process wherein the address space (CLONE_VM), file system information(CLONE_FS), files that are opened(CLONE_FILES), and signals that are pending(CLONE_SIGHAND) will be shared. This is the reason why I earlier mentioned that clone() system call is versatile in nature. You can share whatever you like while creating a new process. Actually you can even create things that are not processes or even threads, because of the flexible nature of clone system call in Linux.
POSIX (portable operating system interface) is a set of standards governing operating systems(based on unix). There needs to be a standard for interoperability. There is a standard for programming interface, for shell and for almost everything in the operating system. Similarly, there is a standard for threads as well. The initial thread implementation in Linux, did not fully comply with POSIX standard.
There were some major reasons why Linux initial thread implementation did not comply with POSIX. One main reason is PID. Earlier implementation of threads had different PID numbers(similar to how processes had different PIDs).
To fix these issues in the thread implementation, Red Hat started something called NPTL(Native Posix Thread Library), which later on was included in the Linux kernel (starting from 2.6 version of the kernel). The library function to create threads was also included in the GNU C library. The library function is called as pthread_create.
Although you can use clone system call to create a thread, it is recommended to use pthread_create. This is for portability reasons (It is not necessary that a variant of Unix will have clone() system call available. However, the pthread_create library can still be used, as it will take care of the underlying system call and other complexities).
Each thread has a task_struct, similar to processes. So kernel will schedule these similar to processes (of course switching between threads is super fact compared to switching between processes).
pthread_create internally uses clone() system call only.
How to see threads associated with a process in Linux?
In the ps command man pages, you will see something like the below for threads.
To get info about threads: ps -eLf ps axms
So let us try that. On one of my servers, i have a mongodb server running with multiple threads, that should be a good example. See below.
[root@localhost ~]# ps -efL |grep mongo root 1470 1 1470 0 19 11:25 ? 00:00:11 /opt/mongodb-linux-x86_64-rhel62-3.0.4/bin/mongod --bind_ip 10.12.1.132 --dbpath /mnt/mongodb_data --fork --logpath /mnt/mongodb.log root 1470 1 1471 0 19 11:25 ? 00:00:00 /opt/mongodb-linux-x86_64-rhel62-3.0.4/bin/mongod --bind_ip 10.12.1.132 --dbpath /mnt/mongodb_data --fork --logpath /mnt/mongodb.log root 1470 1 1472 0 19 11:25 ? 00:00:00 /opt/mongodb-linux-x86_64-rhel62-3.0.4/bin/mongod --bind_ip 10.12.1.132 --dbpath /mnt/mongodb_data --fork --logpath /mnt/mongodb.log root 1470 1 1473 0 19 11:25 ? 00:00:00 /opt/mongodb-linux-x86_64-rhel62-3.0.4/bin/mongod --bind_ip 10.12.1.132 --dbpath /mnt/mongodb_data --fork --logpath /mnt/mongodb.log root 1470 1 1474 0 19 11:25 ? 00:00:06 /opt/mongodb-linux-x86_64-rhel62-3.0.4/bin/mongod --bind_ip 10.12.1.132 --dbpath /mnt/mongodb_data --fork --logpath /mnt/mongodb.log
From the above output, you can see that all of those processes has got the same PID number (1470). However, they have a unique number thread id numbers(1470, 1471, 1472, 1473, 1474).
In Linux, these thread id numbers are indicated by LWP (the ps command column name is also LWP). LWP stands for Light Weight Process.
Actually...In linux, every program has at least one thread.
[root@localhost ~]# ps -efL UID PID PPID LWP C NLWP STIME TTY TIME CMD root 1 0 1 0 1 09:19 ? 00:00:01 /sbin/init root 2 0 2 0 1 09:19 ? 00:00:00 [kthreadd] root 3 2 3 0 1 09:19 ? 00:00:00 [migration/0] root 4 2 4 0 1 09:19 ? 00:00:00 [ksoftirqd/0] root 5 2 5 0 1 09:19 ? 00:00:00 [stopper/0] root 6 2 6 0 1 09:19 ? 00:00:00 [watchdog/0] root 7 2 7 0 1 09:19 ? 00:00:00 [migration/1] root 8 2 8 0 1 09:19 ? 00:00:00 [stopper/1] root 9 2 9 0 1 09:19 ? 00:00:00 [ksoftirqd/1] root 10 2 10 0 1 09:19 ? 00:00:00 [watchdog/1] root 11 2 11 0 1 09:19 ? 00:00:00 [events/0] root 12 2 12 0 1 09:19 ? 00:00:00 [events/1]
In single threaded programs, LWP number and PID numbers are always same. One thread, one process is what happens in most cases.
TGID, or thread group identifier was introduced for implementing POSIX compliant threads in Linux. Thread group identifier is generally the PID number of the main process.
If a process has 4 threads, all of those thread's task_struct will have TGID set to the PID of the main process id(or call it the first thread).
 Sarath Pillai
Sarath Pillai Satish Tiwary
Satish Tiwary
Comments
This site is awesome..you
This site is awesome..you guys explain things in pretty easy way..
Thanks a lot keep going..
Add new comment